Netty
1. source
版本netty-all-4.1.34.Final。
官方架构图:
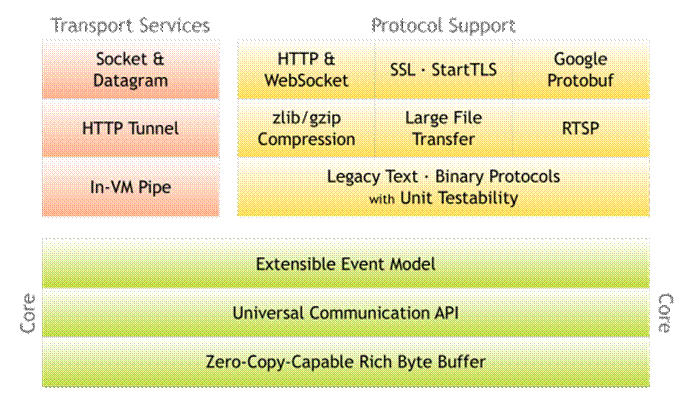
使用Reactor 模型
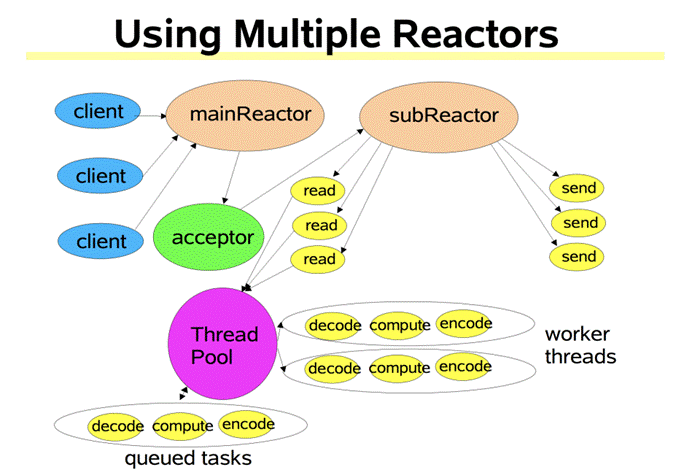
2. Reactor
2.1 Acceptor
io.netty.bootstrap. ServerBootstrap. ServerBootstrapAcceptor的channelRead方法
public void channelRead(ChannelHandlerContext ctx, Object msg) {
final Channel child = (Channel) msg;
child.pipeline().addLast(childHandler);
setChannelOptions(child, childOptions, logger);
for (Entry<AttributeKey<?>, Object> e: childAttrs) {
child.attr((AttributeKey<Object>) e.getKey()).set(e.getValue());
}
try {
childGroup.register(child).addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
if (!future.isSuccess()) {
forceClose(child, future.cause());
}
}
});
} catch (Throwable t) {
forceClose(child, t);
}
}
2.2 Reactor
io.netty.bootstrap. ServerBootstrap. ServerBootstrapAcceptor的init方法。
void init(Channel channel) throws Exception {
final Map<ChannelOption<?>, Object> options = options0();
synchronized (options) {
setChannelOptions(channel, options, logger);
}
final Map<AttributeKey<?>, Object> attrs = attrs0();
synchronized (attrs) {
for (Entry<AttributeKey<?>, Object> e: attrs.entrySet()) {
@SuppressWarnings("unchecked")
AttributeKey<Object> key = (AttributeKey<Object>) e.getKey();
channel.attr(key).set(e.getValue());
}
}
ChannelPipeline p = channel.pipeline();
final EventLoopGroup currentChildGroup = childGroup;
final ChannelHandler currentChildHandler = childHandler;
final Entry<ChannelOption<?>, Object>[] currentChildOptions;
final Entry<AttributeKey<?>, Object>[] currentChildAttrs;
synchronized (childOptions) {
currentChildOptions = childOptions.entrySet().toArray(newOptionArray(0));
}
synchronized (childAttrs) {
currentChildAttrs = childAttrs.entrySet().toArray(newAttrArray(0));
}
p.addLast(new ChannelInitializer<Channel>() {
@Override
public void initChannel(final Channel ch) throws Exception {
final ChannelPipeline pipeline = ch.pipeline();
ChannelHandler handler = config.handler();
if (handler != null) {
pipeline.addLast(handler);
}
ch.eventLoop().execute(new Runnable() {
@Override
public void run() {
pipeline.addLast(new ServerBootstrapAcceptor(
ch, currentChildGroup, currentChildHandler, currentChildOptions, currentChildAttrs));
}
});
}
});
}
2.3 Select Event
io.netty.channel.nio.NioEventLoop的run方法
protected void run() {
for (;;) {
try {
try {
switch (selectStrategy.calculateStrategy(selectNowSupplier, hasTasks())) {
case SelectStrategy.CONTINUE:
continue;
case SelectStrategy.BUSY_WAIT:
case SelectStrategy.SELECT:
select(wakenUp.getAndSet(false));
if (wakenUp.get()) {
selector.wakeup();
}
// fall through
default:
}
} catch (IOException e) {
rebuildSelector0();
handleLoopException(e);
continue;
}
cancelledKeys = 0;
needsToSelectAgain = false;
final int ioRatio = this.ioRatio;
if (ioRatio == 100) {
try {
processSelectedKeys();
} finally {
// Ensure we always run tasks.
runAllTasks();
}
} else {
final long ioStartTime = System.nanoTime();
try {
processSelectedKeys();
} finally {
// Ensure we always run tasks.
final long ioTime = System.nanoTime() - ioStartTime;
runAllTasks(ioTime * (100 - ioRatio) / ioRatio);
}
}
} catch (Throwable t) {
handleLoopException(t);
}
// Always handle shutdown even if the loop processing threw an exception.
try {
if (isShuttingDown()) {
closeAll();
if (confirmShutdown()) {
return;
}
}
} catch (Throwable t) {
handleLoopException(t);
}
}
}
io.netty.channel.nio.NioEventLoop的select方法。
private void select(boolean oldWakenUp) throws IOException {
Selector selector = this.selector;
try {
int selectCnt = 0;
long currentTimeNanos = System.nanoTime();
long selectDeadLineNanos = currentTimeNanos + delayNanos(currentTimeNanos);
for (;;) {
long timeoutMillis = (selectDeadLineNanos - currentTimeNanos + 500000L) / 1000000L;
if (timeoutMillis <= 0) {
if (selectCnt == 0) {
selector.selectNow();
selectCnt = 1;
}
break;
}
if (hasTasks() && wakenUp.compareAndSet(false, true)) {
selector.selectNow();
selectCnt = 1;
break;
}
int selectedKeys = selector.select(timeoutMillis);
selectCnt ++;
if (selectedKeys != 0 || oldWakenUp || wakenUp.get() || hasTasks() || hasScheduledTasks()) {
break;
}
if (Thread.interrupted()) {
if (logger.isDebugEnabled()) {
logger.debug("Selector.select() returned prematurely because " +
"Thread.currentThread().interrupt() was called. Use " +
"NioEventLoop.shutdownGracefully() to shutdown the NioEventLoop.");
}
selectCnt = 1;
break;
}
long time = System.nanoTime();
if (time - TimeUnit.MILLISECONDS.toNanos(timeoutMillis) >= currentTimeNanos) {
// timeoutMillis elapsed without anything selected.
selectCnt = 1;
} else if (SELECTOR_AUTO_REBUILD_THRESHOLD > 0 &&
selectCnt >= SELECTOR_AUTO_REBUILD_THRESHOLD) {
// The code exists in an extra method to ensure the method is not too big to inline as this
// branch is not very likely to get hit very frequently.
selector = selectRebuildSelector(selectCnt);
selectCnt = 1;
break;
}
currentTimeNanos = time;
}
if (selectCnt > MIN_PREMATURE_SELECTOR_RETURNS) {
if (logger.isDebugEnabled()) {
logger.debug("Selector.select() returned prematurely {} times in a row for Selector {}.",
selectCnt - 1, selector);
}
}
} catch (CancelledKeyException e) {
if (logger.isDebugEnabled()) {
logger.debug(CancelledKeyException.class.getSimpleName() + " raised by a Selector {} - JDK bug?",
selector, e);
}
// Harmless exception - log anyway
}
}
3. Handler
3.1 ChannelPipeline
ChannelPipeline基本流程:
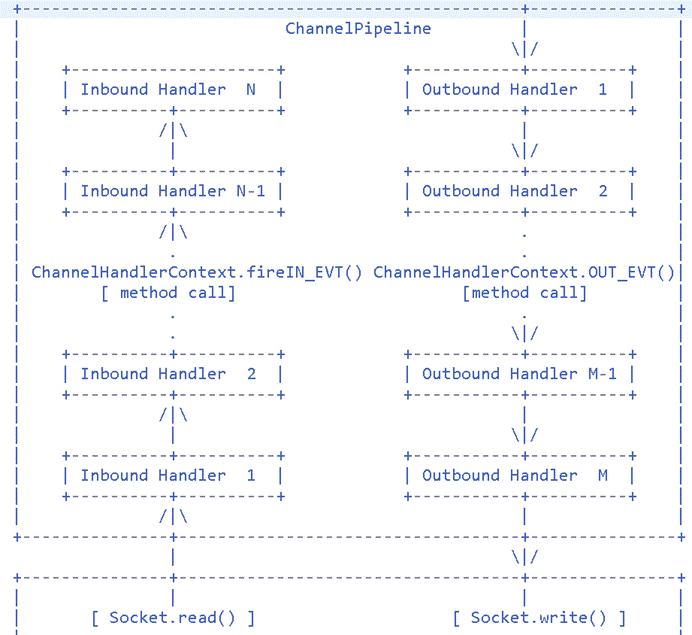
Netty Internal I/O Threads (Transport Implementation)
io.netty.channel.DefaultChannelPipeline的addFirst方法
private static void addAfter0(AbstractChannelHandlerContext ctx, AbstractChannelHandlerContext newCtx) {
newCtx.prev = ctx;
newCtx.next = ctx.next;
ctx.next.prev = newCtx;
ctx.next = newCtx;
}
public final ChannelPipeline addFirst(ChannelHandler handler) {
return addFirst(null, handler);
}
3.2 Handler
io.netty.channel.ChannelHandler中的ChannelHandlerContext 链表
public interface ChannelHandler {
void handlerAdded(ChannelHandlerContext ctx) throws Exception;
void handlerRemoved(ChannelHandlerContext ctx) throws Exception;
@Deprecated
void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception;
@Inherited
@Documented
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@interface Sharable {
// no value
}
}
io.netty.channel. ChannelHandlerContext中的各种方法
public interface ChannelHandlerContext extends AttributeMap, ChannelInboundInvoker, ChannelOutboundInvoker {
Channel channel();
EventExecutor executor();
String name();
ChannelHandler handler();
boolean isRemoved();
ChannelHandlerContext fireChannelRegistered();
ChannelHandlerContext fireChannelUnregistered();
ChannelHandlerContext fireChannelActive();
ChannelHandlerContext fireChannelInactive();
ChannelHandlerContext fireExceptionCaught(Throwable cause);
ChannelHandlerContext fireUserEventTriggered(Object evt);
ChannelHandlerContext fireChannelRead(Object msg);
ChannelHandlerContext fireChannelReadComplete();
ChannelHandlerContext fireChannelWritabilityChanged();
ChannelHandlerContext read();
ChannelHandlerContext flush();
ChannelPipeline pipeline();
ByteBufAllocator alloc();
<T> Attribute<T> attr(AttributeKey<T> key);
<T> boolean hasAttr(AttributeKey<T> key);
}
3.3 event
3.3.1 Read event
io.netty.channel. AbstractChannelHandlerContext中的fireChannelRead方法,通过Runnable的事件进行
@Override
public ChannelHandlerContext fireChannelRead(final Object msg) {
invokeChannelRead(findContextInbound(), msg);
return this;
}
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) {
final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
next.invokeChannelRead(m);
} else {
executor.execute(new Runnable() {
@Override
public void run() {
next.invokeChannelRead(m);
}
});
}
}
private void invokeChannelRead(Object msg) {
if (invokeHandler()) {
try {
((ChannelInboundHandler) handler()).channelRead(this, msg);
} catch (Throwable t) {
notifyHandlerException(t);
}
} else {
fireChannelRead(msg);
}
} }
3.3.2 write event
io.netty.channel. AbstractChannelHandlerContext中的write方法,通过Runnable的事件进行
private void write(Object msg, boolean flush, ChannelPromise promise) {
ObjectUtil.checkNotNull(msg, "msg");
try {
if (isNotValidPromise(promise, true)) {
ReferenceCountUtil.release(msg);
// cancelled
return;
}
} catch (RuntimeException e) {
ReferenceCountUtil.release(msg);
throw e;
}
AbstractChannelHandlerContext next = findContextOutbound();
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
final AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = WriteTask.newInstance(next, m, promise);
}
if (!safeExecute(executor, task, promise, m)) {
task.cancel();
}
}
}}
4. Zero-Copy
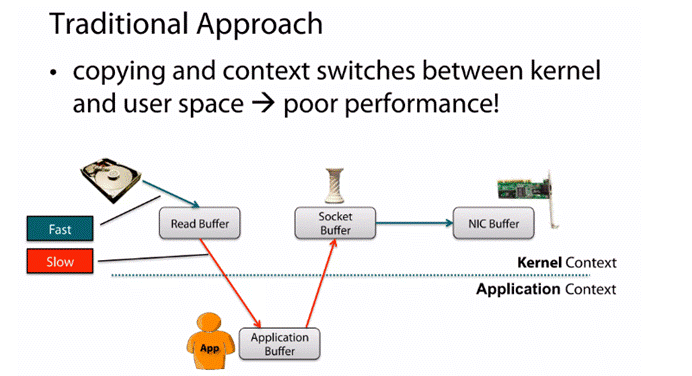
4.1 transferTo
io.netty.channel. DefaultFileRegion中的transferTo方法,
public long transferTo(WritableByteChannel target, long position) throws IOException {
long count = this.count - position;
if (count < 0 || position < 0) {
throw new IllegalArgumentException(
"position out of range: " + position +
" (expected: 0 - " + (this.count - 1) + ')');
}
if (count == 0) {
return 0L;
}
if (refCnt() == 0) {
throw new IllegalReferenceCountException(0);
}
open();
long written = file.transferTo(this.position + position, count, target);
if (written > 0) {
transferred += written;
} else if (written == 0) {
validate(this, position);
}
return written;
}
java.nio.channels.FileChannel中的transferTo方法,
public abstract long transferTo(long position, long count,
WritableByteChannel target)
throws IOException;
4.2 WrappedByteBuf
java.nio.channels.FileChannel中的transferTo方法,
public abstract long transferTo(long position, long count,
WritableByteChannel target)
throws IOException;

io.netty.buffer. Unpooled中的wrappedBuffer方法,
public static ByteBuf wrappedBuffer(byte[] array) {
if (array.length == 0) {
return EMPTY_BUFFER;
}
return new UnpooledHeapByteBuf(ALLOC, array, array.length);
}
public static ByteBuf wrappedBuffer(ByteBuf... buffers) {
return wrappedBuffer(buffers.length, buffers);
}
io.netty.buffer. Unpooled中的wrappedBuffer方法,
public static ByteBuf wrappedBuffer(int maxNumComponents, ByteBuf... buffers) {
switch (buffers.length) {
case 0:
break;
case 1:
ByteBuf buffer = buffers[0];
if (buffer.isReadable()) {
return wrappedBuffer(buffer.order(BIG_ENDIAN));
} else {
buffer.release();
}
break;
default:
for (int i = 0; i < buffers.length; i++) {
ByteBuf buf = buffers[i];
if (buf.isReadable()) {
return new CompositeByteBuf(ALLOC, false, maxNumComponents, buffers, i);
}
buf.release();
}
break;
}
return EMPTY_BUFFER;
}
4.3 CompositeByteBuf
io.netty.buffer. CompositeByteBuf中的构造方法,
private Component[] components; // resized when needed
CompositeByteBuf(ByteBufAllocator alloc, boolean direct, int maxNumComponents,
ByteBuf[] buffers, int offset) {
this(alloc, direct, maxNumComponents, buffers.length - offset);
addComponents0(false, 0, buffers, offset);
consolidateIfNeeded();
setIndex0(0, capacity());
}
io.netty.buffer. CompositeByteBuf中的addComponents0方法,
private CompositeByteBuf addComponents0(boolean increaseWriterIndex,
final int cIndex, ByteBuf[] buffers, int arrOffset) {
final int len = buffers.length, count = len - arrOffset;
int ci = Integer.MAX_VALUE;
try {
checkComponentIndex(cIndex);
shiftComps(cIndex, count); // will increase componentCount
int nextOffset = cIndex > 0 ? components[cIndex - 1].endOffset : 0;
for (ci = cIndex; arrOffset < len; arrOffset++, ci++) {
ByteBuf b = buffers[arrOffset];
if (b == null) {
break;
}
Component c = newComponent(b, nextOffset);
components[ci] = c;
nextOffset = c.endOffset;
}
return this;
} finally {
if (ci < componentCount) {
if (ci < cIndex + count) {
// we bailed early
removeCompRange(ci, cIndex + count);
for (; arrOffset < len; ++arrOffset) {
ReferenceCountUtil.safeRelease(buffers[arrOffset]);
}
}
updateComponentOffsets(ci); // only need to do this here for components after the added ones
}
if (increaseWriterIndex && ci > cIndex && ci <= componentCount) {
writerIndex(writerIndex() + components[ci - 1].endOffset - components[cIndex].offset);
}
}
}
5. BufAllocator
new PooledByteBufAllocator(true);//池化直接内存
new PooledByteBufAllocator(false);//池化堆内存
new UnpooledByteBufAllocator(true);//非池化直接内存
new UnpooledByteBufAllocator(false);//非池化堆内存
5.1 PooledByteBufAllocator
io.netty.buffer. PooledByteBufAllocator中的newHeapBuffer方法HeapBuffer分配内存。
@Override
protected ByteBuf newHeapBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = threadCache.get();
PoolArena<byte[]> heapArena = cache.heapArena;
final ByteBuf buf;
if (heapArena != null) {
buf = heapArena.allocate(cache, initialCapacity, maxCapacity);
} else {
buf = PlatformDependent.hasUnsafe() ?
new UnpooledUnsafeHeapByteBuf(this, initialCapacity, maxCapacity) :
new UnpooledHeapByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer(buf);
}
io.netty.buffer.PooledByteBufAllocator中的newDirectBuffer方法DirectBuffer分配内存。
@Override
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = threadCache.get();
PoolArena<ByteBuffer> directArena = cache.directArena;
final ByteBuf buf;
if (directArena != null) {
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else {
buf = PlatformDependent.hasUnsafe() ?
UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity) :
new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer(buf);
}
5.1.1 PoolArena
io.netty.buffer. PoolArena中的对象属性:PoolSubpage 与PoolChunkList。
abstract class PoolArena<T> implements PoolArenaMetric {
static final boolean HAS_UNSAFE = PlatformDependent.hasUnsafe();
enum SizeClass {
Tiny,
Small,
Normal
}
static final int numTinySubpagePools = 512 >>> 4;
final PooledByteBufAllocator parent;
private final int maxOrder;
final int pageSize;
final int pageShifts;
final int chunkSize;
final int subpageOverflowMask;
final int numSmallSubpagePools;
final int directMemoryCacheAlignment;
final int directMemoryCacheAlignmentMask;
private final PoolSubpage<T>[] tinySubpagePools;
private final PoolSubpage<T>[] smallSubpagePools;
private final PoolChunkList<T> q050;
private final PoolChunkList<T> q025;
private final PoolChunkList<T> q000;
private final PoolChunkList<T> qInit;
private final PoolChunkList<T> q075;
private final PoolChunkList<T> q100;
io.netty.buffer. PoolArena中的PoolArena构造方法初始化最小tinySubpagePools与最大smallSubpagePools。
protected PoolArena(PooledByteBufAllocator parent, int pageSize,
int maxOrder, int pageShifts, int chunkSize, int cacheAlignment) {
this.parent = parent;
this.pageSize = pageSize;
this.maxOrder = maxOrder;
this.pageShifts = pageShifts;
this.chunkSize = chunkSize;
directMemoryCacheAlignment = cacheAlignment;
directMemoryCacheAlignmentMask = cacheAlignment - 1;
subpageOverflowMask = ~(pageSize - 1);
tinySubpagePools = newSubpagePoolArray(numTinySubpagePools);
for (int i = 0; i < tinySubpagePools.length; i ++) {
tinySubpagePools[i] = newSubpagePoolHead(pageSize);
}
numSmallSubpagePools = pageShifts - 9;
smallSubpagePools = newSubpagePoolArray(numSmallSubpagePools);
for (int i = 0; i < smallSubpagePools.length; i ++) {
smallSubpagePools[i] = newSubpagePoolHead(pageSize);
}
q100 = new PoolChunkList<T>(this, null, 100, Integer.MAX_VALUE, chunkSize);
q075 = new PoolChunkList<T>(this, q100, 75, 100, chunkSize);
q050 = new PoolChunkList<T>(this, q075, 50, 100, chunkSize);
q025 = new PoolChunkList<T>(this, q050, 25, 75, chunkSize);
q000 = new PoolChunkList<T>(this, q025, 1, 50, chunkSize);
qInit = new PoolChunkList<T>(this, q000, Integer.MIN_VALUE, 25, chunkSize);
q100.prevList(q075);
q075.prevList(q050);
q050.prevList(q025);
q025.prevList(q000);
q000.prevList(null);
qInit.prevList(qInit);
List<PoolChunkListMetric> metrics = new ArrayList<PoolChunkListMetric>(6);
metrics.add(qInit);
metrics.add(q000);
metrics.add(q025);
metrics.add(q050);
metrics.add(q075);
metrics.add(q100);
chunkListMetrics = Collections.unmodifiableList(metrics);
}
io.netty.buffer.PoolAren中allocate方法,分配PoolSubpage
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
final int normCapacity = normalizeCapacity(reqCapacity);
if (isTinyOrSmall(normCapacity)) { // capacity < pageSize
int tableIdx;
PoolSubpage<T>[] table;
boolean tiny = isTiny(normCapacity);
if (tiny) { // < 512
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
tableIdx = tinyIdx(normCapacity);
table = tinySubpagePools;
} else {
if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
tableIdx = smallIdx(normCapacity);
table = smallSubpagePools;
}
final PoolSubpage<T> head = table[tableIdx];
/**
* Synchronize on the head. This is needed as {@link PoolChunk#allocateSubpage(int)} and
* {@link PoolChunk#free(long)} may modify the doubly linked list as well.
*/
synchronized (head) {
final PoolSubpage<T> s = head.next;
if (s != head) {
assert s.doNotDestroy && s.elemSize == normCapacity;
long handle = s.allocate();
assert handle >= 0;
s.chunk.initBufWithSubpage(buf, null, handle, reqCapacity);
incTinySmallAllocation(tiny);
return;
}
}
synchronized (this) {
allocateNormal(buf, reqCapacity, normCapacity);
}
incTinySmallAllocation(tiny);
return;
}
if (normCapacity <= chunkSize) {
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
synchronized (this) {
allocateNormal(buf, reqCapacity, normCapacity);
++allocationsNormal;
}
} else {
// Huge allocations are never served via the cache so just call allocateHuge
allocateHuge(buf, reqCapacity);
}
}
io.netty.buffer.PoolAren中allocateNormal方法,分配PoolChunk
private void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) ||
q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) ||
q075.allocate(buf, reqCapacity, normCapacity)) {
return;
}
// Add a new chunk.
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
boolean success = c.allocate(buf, reqCapacity, normCapacity);
assert success;
qInit.add(c);
}
io.netty.buffer.PoolAren中free方法,释放内存PoolChunk
void free(PoolChunk<T> chunk, ByteBuffer nioBuffer, long handle, int normCapacity, PoolThreadCache cache) {
if (chunk.unpooled) {
int size = chunk.chunkSize();
destroyChunk(chunk);
activeBytesHuge.add(-size);
deallocationsHuge.increment();
} else {
SizeClass sizeClass = sizeClass(normCapacity);
if (cache != null && cache.add(this, chunk, nioBuffer, handle, normCapacity, sizeClass)) {
// cached so not free it.
return;
}
freeChunk(chunk, handle, sizeClass, nioBuffer, false);
}
}
private SizeClass sizeClass(int normCapacity) {
if (!isTinyOrSmall(normCapacity)) {
return SizeClass.Normal;
}
return isTiny(normCapacity) ? SizeClass.Tiny : SizeClass.Small;
}
void freeChunk(PoolChunk<T> chunk, long handle, SizeClass sizeClass, ByteBuffer nioBuffer, boolean finalizer) {
final boolean destroyChunk;
synchronized (this) {
// We only call this if freeChunk is not called because of the PoolThreadCache finalizer as otherwise this
// may fail due lazy class-loading in for example tomcat.
if (!finalizer) {
switch (sizeClass) {
case Normal:
++deallocationsNormal;
break;
case Small:
++deallocationsSmall;
break;
case Tiny:
++deallocationsTiny;
break;
default:
throw new Error();
}
}
destroyChunk = !chunk.parent.free(chunk, handle, nioBuffer);
}
if (destroyChunk) {
// destroyChunk not need to be called while holding the synchronized lock.
destroyChunk(chunk);
}
}
5.1.2 PoolSubpage
io.netty.buffer. PoolSubpage的主要属性
final class PoolSubpage<T> implements PoolSubpageMetric {
final PoolChunk<T> chunk;
private final int memoryMapIdx;
private final int runOffset;
private final int pageSize;
private final long[] bitmap;
PoolSubpage<T> prev;
PoolSubpage<T> next;
}
5.1.3 PoolChunk
io.netty.buffer. PoolChunk的主要属性
final class PoolChunk<T> implements PoolChunkMetric {
private static final int INTEGER_SIZE_MINUS_ONE = Integer.SIZE - 1;
final PoolArena<T> arena;
final T memory;
final boolean unpooled;
final int offset;
private final byte[] memoryMap;
private final byte[] depthMap;
private final PoolSubpage<T>[] subpages;
/** Used to determine if the requested capacity is equal to or greater than pageSize. */
private final int subpageOverflowMask;
private final int pageSize;
private final int pageShifts;
private final int maxOrder;
private final int chunkSize;
private final int log2ChunkSize;
private final int maxSubpageAllocs;
/** Used to mark memory as unusable */
private final byte unusable;
private final Deque<ByteBuffer> cachedNioBuffers;
private int freeBytes;
PoolChunkList<T> parent;
PoolChunk<T> prev;
PoolChunk<T> next;
}
5.1.4 HeapArena
io.netty.buffer. PoolArena. HeapArena的byte[]方式分配方式
static final class HeapArena extends PoolArena<byte[]> {
HeapArena(PooledByteBufAllocator parent, int pageSize, int maxOrder,
int pageShifts, int chunkSize, int directMemoryCacheAlignment) {
super(parent, pageSize, maxOrder, pageShifts, chunkSize,
directMemoryCacheAlignment);
}
private static byte[] newByteArray(int size) {
return PlatformDependent.allocateUninitializedArray(size);
}
@Override
boolean isDirect() {
return false;
}
@Override
protected PoolChunk<byte[]> newChunk(int pageSize, int maxOrder, int pageShifts, int chunkSize) {
return new PoolChunk<byte[]>(this, newByteArray(chunkSize), pageSize, maxOrder, pageShifts, chunkSize, 0);
}
@Override
protected PoolChunk<byte[]> newUnpooledChunk(int capacity) {
return new PoolChunk<byte[]>(this, newByteArray(capacity), capacity, 0);
}
@Override
protected void destroyChunk(PoolChunk<byte[]> chunk) {
// Rely on GC.
}
@Override
protected PooledByteBuf<byte[]> newByteBuf(int maxCapacity) {
return HAS_UNSAFE ? PooledUnsafeHeapByteBuf.newUnsafeInstance(maxCapacity)
: PooledHeapByteBuf.newInstance(maxCapacity);
}
@Override
protected void memoryCopy(byte[] src, int srcOffset, byte[] dst, int dstOffset, int length) {
if (length == 0) {
return;
}
System.arraycopy(src, srcOffset, dst, dstOffset, length);
}
}
5.1.5 DirectArena
io.netty.buffer. PoolArena. DirectArena的ByteBuffer方式分配chunk
static final class DirectArena extends PoolArena<ByteBuffer> {
DirectArena(PooledByteBufAllocator parent, int pageSize, int maxOrder,
int pageShifts, int chunkSize, int directMemoryCacheAlignment) {
super(parent, pageSize, maxOrder, pageShifts, chunkSize,
directMemoryCacheAlignment);
}
@Override
boolean isDirect() {
return true;
}
// mark as package-private, only for unit test
int offsetCacheLine(ByteBuffer memory) {
// We can only calculate the offset if Unsafe is present as otherwise directBufferAddress(...) will
// throw an NPE.
int remainder = HAS_UNSAFE
? (int) (PlatformDependent.directBufferAddress(memory) & directMemoryCacheAlignmentMask)
: 0;
// offset = alignment - address & (alignment - 1)
return directMemoryCacheAlignment - remainder;
}
@Override
protected PoolChunk<ByteBuffer> newChunk(int pageSize, int maxOrder,
int pageShifts, int chunkSize) {
if (directMemoryCacheAlignment == 0) {
return new PoolChunk<ByteBuffer>(this,
allocateDirect(chunkSize), pageSize, maxOrder,
pageShifts, chunkSize, 0);
}
final ByteBuffer memory = allocateDirect(chunkSize
+ directMemoryCacheAlignment);
return new PoolChunk<ByteBuffer>(this, memory, pageSize,
maxOrder, pageShifts, chunkSize,
offsetCacheLine(memory));
}
@Override
protected PoolChunk<ByteBuffer> newUnpooledChunk(int capacity) {
if (directMemoryCacheAlignment == 0) {
return new PoolChunk<ByteBuffer>(this,
allocateDirect(capacity), capacity, 0);
}
final ByteBuffer memory = allocateDirect(capacity
+ directMemoryCacheAlignment);
return new PoolChunk<ByteBuffer>(this, memory, capacity,
offsetCacheLine(memory));
}
private static ByteBuffer allocateDirect(int capacity) {
return PlatformDependent.useDirectBufferNoCleaner() ?
PlatformDependent.allocateDirectNoCleaner(capacity) : ByteBuffer.allocateDirect(capacity);
}
@Override
protected void destroyChunk(PoolChunk<ByteBuffer> chunk) {
if (PlatformDependent.useDirectBufferNoCleaner()) {
PlatformDependent.freeDirectNoCleaner(chunk.memory);
} else {
PlatformDependent.freeDirectBuffer(chunk.memory);
}
}
@Override
protected PooledByteBuf<ByteBuffer> newByteBuf(int maxCapacity) {
if (HAS_UNSAFE) {
return PooledUnsafeDirectByteBuf.newInstance(maxCapacity);
} else {
return PooledDirectByteBuf.newInstance(maxCapacity);
}
}
@Override
protected void memoryCopy(ByteBuffer src, int srcOffset, ByteBuffer dst, int dstOffset, int length) {
if (length == 0) {
return;
}
if (HAS_UNSAFE) {
PlatformDependent.copyMemory(
PlatformDependent.directBufferAddress(src) + srcOffset,
PlatformDependent.directBufferAddress(dst) + dstOffset, length);
} else {
// We must duplicate the NIO buffers because they may be accessed by other Netty buffers.
src = src.duplicate();
dst = dst.duplicate();
src.position(srcOffset).limit(srcOffset + length);
dst.position(dstOffset);
dst.put(src);
}
}
}
5.2 UnpooledByteBufAllocator
io.netty.buffer. UnpooledByteBufAllocator中的newHeapBuffer方法HeapBuffer分配内存。
@Override
protected ByteBuf newHeapBuffer(int initialCapacity, int maxCapacity) {
return PlatformDependent.hasUnsafe() ?
new InstrumentedUnpooledUnsafeHeapByteBuf(this, initialCapacity, maxCapacity) :
new InstrumentedUnpooledHeapByteBuf(this, initialCapacity, maxCapacity);
}
io.netty.buffer. UnpooledByteBufAllocator中的newDirectBuffer方法DirectBuffer分配内存。
@Override
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
final ByteBuf buf;
if (PlatformDependent.hasUnsafe()) {
buf = noCleaner ? new InstrumentedUnpooledUnsafeNoCleanerDirectByteBuf(this, initialCapacity, maxCapacity) :
new InstrumentedUnpooledUnsafeDirectByteBuf(this, initialCapacity, maxCapacity);
} else {
buf = new InstrumentedUnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
return disableLeakDetector ? buf : toLeakAwareBuffer(buf);
}
5.2.1 PoolArena
io.netty.buffer.UnpooledByteBufAllocator.InstrumentedUnpooledUnsafeHeapByteBuf中的allocateArray方法。
private static final class InstrumentedUnpooledUnsafeHeapByteBuf extends UnpooledUnsafeHeapByteBuf {
InstrumentedUnpooledUnsafeHeapByteBuf(UnpooledByteBufAllocator alloc, int initialCapacity, int maxCapacity) {
super(alloc, initialCapacity, maxCapacity);
}
@Override
protected byte[] allocateArray(int initialCapacity) {
byte[] bytes = super.allocateArray(initialCapacity);
((UnpooledByteBufAllocator) alloc()).incrementHeap(bytes.length);
return bytes;
}
}
io.netty.buffer. UnpooledHeapByteBuf中的allocateArray方法。
protected byte[] allocateArray(int initialCapacity) {
return new byte[initialCapacity];
}
}
5.2.2 allocateDirect
io.netty.buffer. UnpooledByteBufAllocator. InstrumentedUnpooledDirectByteBuf中的allocateDirect方法。
private static final class InstrumentedUnpooledDirectByteBuf extends UnpooledDirectByteBuf {
InstrumentedUnpooledDirectByteBuf(
UnpooledByteBufAllocator alloc, int initialCapacity, int maxCapacity) {
super(alloc, initialCapacity, maxCapacity);
}
@Override
protected ByteBuffer allocateDirect(int initialCapacity) {
ByteBuffer buffer = super.allocateDirect(initialCapacity);
((UnpooledByteBufAllocator) alloc()).incrementDirect(buffer.capacity());
return buffer;
}
java.nio. DirectByteBuffer中的直接内存分配
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}