Flink
目录
2.1 无界、有界与流处理、批处理...................................................................... 5
1. Flink发展概要
1.1 历史起源
Flink起源于计算机科学与技术实力很强的德国柏林工业大学。柏林工业大学德国综合排名第8位的大学,2022年QS世界大学排名158名。该校的计算机科学与技术德国第1位,该校的计算机科学与信息系统的世界大学排名73位。
2003年,Google发布Google File System论文《The Google File System 》。
2004发,Google发布大型集群中简化数据处理MapReduce论文《MapReduce: Simplified Data Processing on Large Clusters》。
2006年2月,NDFS(Nutch Distributed File System)从apache Nutch 项目中分离出来,命名为Hadoop。
2006年发表结构化数据的分布式存储系统Bigtable论文《Bigtable: A Distributed Storage System for Structured Data》。
2008年,VolkerMarkl提出了“平流层”的构想。
2009年,Spark诞生于伯克利大学AMPLab,属于伯克利大学的研究性项目。2010 年,通过BSD 许可协议正式对外开源发布。
2010年12月,Nathan首先提出将“流(Stream)”作为一个分布式的抽象概念,然后又提出了“spouts”和“bolts”的想法。
2014年9月17日,Storm正式毕业,升级为顶级项目
2014 年 Stratosphere 项目开发并贡献了一个平台,该平台于 2014 年成为 Apache 项目,名为Apache Flink。
创始团队中的许多成员离开大学并创办了一个公司来实现 Flink 的商业化,他们为这个公司取名为 data Artisans。
2014 年 12 月Apache 软件基金会发布了第一个Release版本Flink0.8.0,一跃成为 Apache 软件基金会的顶级项目。
2015年google在论文《The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing》提出Dataflow模型。
2016 年 2 月份,谷歌及其合作伙伴向 Apache 捐赠了一大批代码,创立了孵化中的 Beam 项目( 最初叫 Apache Dataflow)。
Apache Beam是 Apache 软件基金会于2017年1 月 10 日对外宣布的开源平台。
2019 年 1 月 8 日, 在微软宣布 GitHub 免费开放私有代码库的同一天,阿里巴巴确认收购 德国初创企业 Data Artisan。
阿里巴巴内部 Flink 版本 Blink 将于 2019 年 1 月正式开源!
2014年4月,贡献给Apache软件基金会,更名为Apache Flink;
2014年8月,Flink第一个版本0.6正式发布,与此同时Fink的几位核心开发者创办了Data Artisans公司;
2014年12月,Flink项目完成孵化,成为Apache顶级项目;
2015年4月,Flink发布了里程碑式的重要版本0.9.0;
2019年1月,长期对Flink投入研发的阿里巴巴,以9000万欧元的价格收购了Data Artisans公司;
2019年8月,阿里巴巴将内部版本Blink开源,合并入Flink1.9.0版本;
2020年5月,Apache Flink 1.10.0发布;
2020年7月,Apache Flink 1.11.0发布;
2020年12月,Apache Flink 1.12.0发布
2021年4月,Apache Flink 1.13.0发布;
2021年9月,Apache Flink 1.14.0发布;
1.2 业界动态
随着实时计算需求的迫切性,各种迭代计算的性能以及对流式计算和SQL的支持,以Spark Streming为例也支持流式计算,而且能解决99%的流式计算要求,但是Spark Streaming设计理念里面认为流是批的极限,即微批(micro-batch)就是流式,所以有个致命的缺点就是攒批;因为这个缺点的存在,剩下的1%的流式运算并不太适合Spark,而Flink就很好的规避了这个缺点,认为批是流的特例,把数据计算归为有界和无界的,有界的数据就是批处理,无界的数据就是流式,而且以流批一体为终极计算目标,Flink就被归在第四类内,从这里开始时就正式揭开Flink的面纱!
量子计算机可以识别大数据集中的模式</strong></p><p>预计量子计算将能够搜索非常大的、未排序的数据集,以非常快的速度发现模式或异常。量子计算机可以同时访问数据库中的所有条目,从而在几秒钟内识别出这些相似点。虽然这在理论上是可能的,但它只发生在一个并行的计算机上,并且只能以一个接一个的方式查看每个记录,所以它花费了大量的时间,并且取决于数据集的大小,它可能永远不会成为现实。
量子计算机可以帮助整合不同数据集的数据。此外,由于可被用于整合不同的数据集,量子计算机有望获得巨大突破。虽然这在没有人类介入的情况下可能是困难的,但是人类的参与将帮助计算机学会如何在未来整合数据。因此,如果有不同独特模式的原始数据源,并有研究团队想要比较它们,那么在数据被比较值钱,计算机就必须理解模式之间的关系。为了实现这个目标,需要在分析自然语言的语义方面取得突破,而这正是AI面临的最大挑战之一。然而,人类可以提供输入,然后对未来系统进行训练。</p><p>最终,量子计算机将允许快速分析和整合庞大的数据集,这些数据集将改进和改变我们的机器学习和AI能力。
2. 基本思想
2.1 无界、有界与流处理、批处理
在描述无限和有限数据集时,DataFlow使用无界和有界这样的描述,而不是流处理数据和批处理数据,这是因为流处理和批处理意味着使用特定的执行引擎。实际上,无界数据集可以通过批处理系统反复调度来处理,而设计良好的流处理系统也可以完美地处理有界数据集。从这个角度来看,区分流处理和批处理的实际意义不大,这也为后来Flink流批一体架构提供了理论基础。
DataStream API和DataSet API主要面向具有开发经验的用户,用户可以使用DataStream API处理无界流数据,使用DataSet API处理批量数据。
2.2 有界流
有定义流的开始,也有定义流的结束。
有界流可以在摄取所有数据后再进行计算。
有界流所有数据可以被排序,所以并不需要有序摄取。
有界流处理通常被称为批处理。
有界流,Flink则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
2.3 无界流
有定义流的开始,但没有定义流的结束。
它们会无休止地产生数据。
无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。
处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
Flink 擅长精确的时间控制和状态化,使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。
3. 基本原理
JobManager 主要负责调度 Job 并协调 Task 做 checkpoint,职责上很像 Storm 的 Nimbus。从 Client 处接收到 Job 和 JAR 包 等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,Task 为线程。从 JobManager 处接收需要 部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
4. 基本结构
4.1 Flink的执行图
Flink会根据代码执行流程生成DAG数据流图,生成顺序为:streamGraph、jobGraph、executionGraph、物理执行图
1、streamGraph:程序原始执行流程图,也就是算子的依赖关系,在client上生成
2、jobGraph:对程序执行流程图进行一定程度的优化,如将one to one的operator生成operator chain,在client上生成
3、executionGraph:对程序中设置的并行度和提交的资源进行并行规划,在jobManager上生成
4、物理执行图:将executionGraph的并行计划落实到taskManager上,将subTask落实到具体的taskSlot上。
4.2 Flink编程模式
Flink程序的基本构建块是流(streams )和转换(transformations)。从概念上讲,流(streams )是数据记录的流(flow)(可能是永无休止的),而转换(transformations)是将一个或多个流作为输入,并产生一个或多个输出流的操作。
当执行时,Flink程序被映射为流动的数据流(streaming dataflows),包括流和转换操作符。每个数据流(dataflow)从一个或多个源(sources )开始,以一个或多个接收(sinks)结束。数据流(dataflow)类似于任意有向无环图(DAGs)。尽管通过迭代构造允许特殊形式的环(cycles ),但为了简单起见,我们在大多数情况下将忽略这一点,也就是仍然看成有向无环图(笔者注)。下面看个例子:下面看个例子:
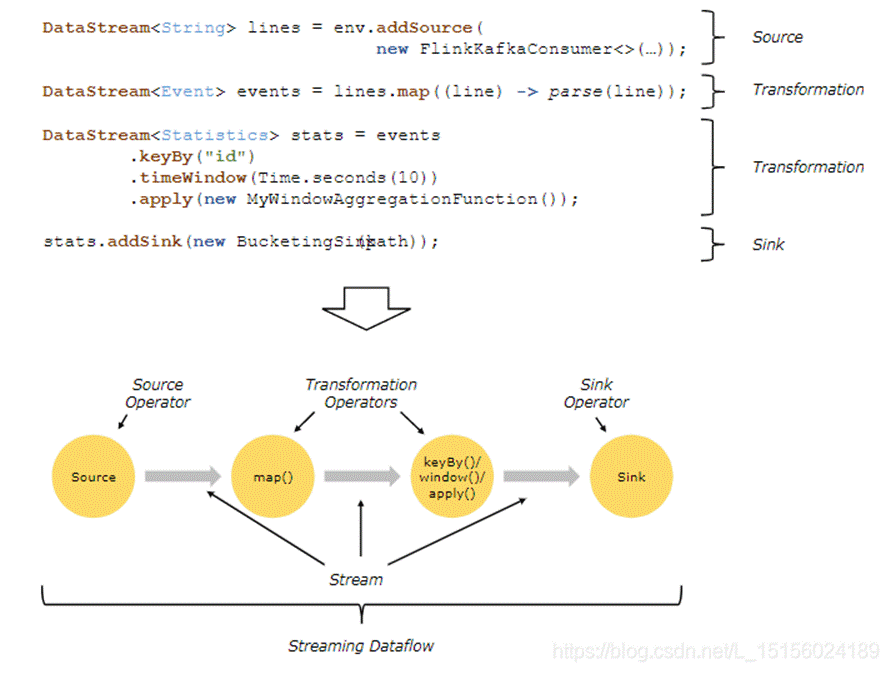
图的上半部分是程序,主要包含了三个部分:source、transfomation和sink。图的下半部分是程序对应的数据流(dataflow)。
笔者注:本文将DataStream和Dataflow都翻译为数据流, 从图中能看出它俩的本质区别,DataStream是真实数据记录的抽象,而Dataflow是程序对应的一个有向无环图。如无特殊标注,数据流指的都是DataStream。
Flink中的程序本质上是并行(parallel )和分布式的(distributed)。在程序执行期间,一个流(stream)有一个或多个流分区(stream partitions),每个操作(operator )有一个或多个操作子任务(operator subtasks)。操作子任务相互独立,在不同的线程或者可能在不同的机器或容器上执行。
一个操作的并行度(parallelism )指的是操作子任务的数量。流的并行度是产生该流的操作符的并行度。同一个程序的不同操作可能具有不同的并行度。如图:
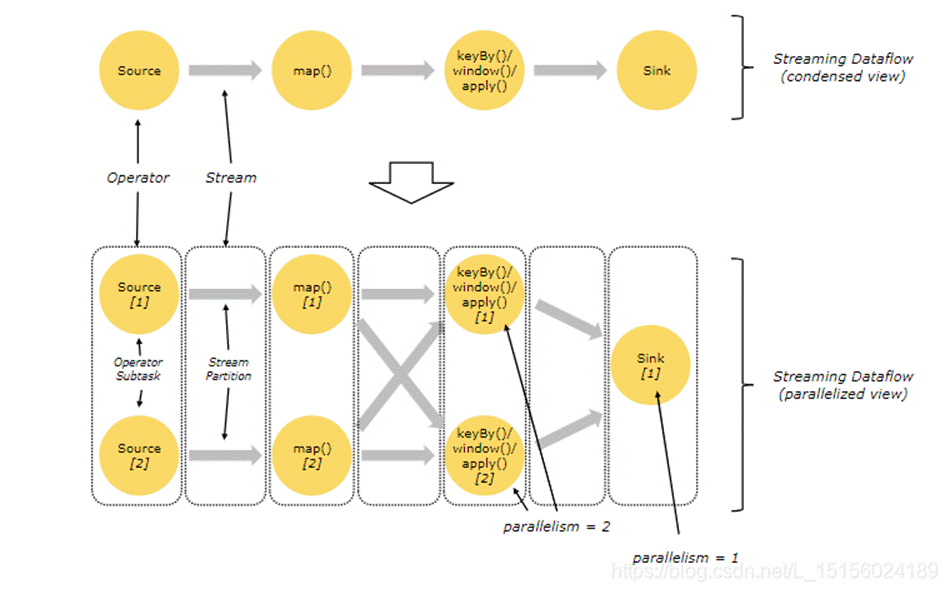
图的上半部分是简化的Dataflow,下半部分是从并行度角度分析的Dataflow。每个黄色实心圆表示一个操作子任务,灰色箭头表示流。看到,在sink之前并行度都是2,sink的并行度是1。
流可以以一对一模式(one-to-one pattern,也可以叫forwarding pattern)或重分布模式(redistributing pattern)在两个操作符之间传输数据。
(1)One-to-one streams
比如图中Source和map()之间的流就是一个One-to-one stream。它保持元素的分区(partitioning )和顺序(ordering )。这意味着map()操作符的子任务[1](也就是图中的map()[1])将看到与源操作符的子任务[1](也即是图中的Source[1])同样的元素,同样的顺序。
(2)Redistributing streams
比如图中的 map()和keyBy/window之间的流是一个redistributing stream。它更改了流的分区。根据所选择的转换,每个操作子任务(比如map)将数据发送到不同的目标子任务(比如keyBy)。
原文中认为keyBy/window和Sink之间也是一个Redistributing stream。但笔者认为,它应该归属于One-to-one stream,理由是它也是one-to-one,并没有发生Redistributing。
5. 基本状态
Flink处理机制的核心,就是“有状态的流式计算”。之前已经多次提到了“状态”(state),不论是简单聚合、窗口聚合,还是处理函数的应用,都会有状态的身影出现。有状态流处理,状态就如同事务处理时数据库中保存的信息一样,是用来辅助进行任务计算的数据。而在Flink这样的分布式系统中,不仅需要定义出状态在任务并行时的处理方式,还需要考虑如何持久化保存、以便发生故障时正确地恢复。这就需要一套完整的管理机制来处理所有的状态。在流处理中,数据是连续不断到来和处理的。每个任务进行计算处理时,可以基于当前数据直接转换得到输出结果;也可以依赖一些其他数据。这些由一个任务维护,并且用来计算输出结果的所有数据,就叫作这个任务的状态。
1、有状态算子
在Flink中,算子任务可以分为无状态和有状态两种情况。无状态的算子任务只需要观察每个独立事件,根据当前输入的数据直接转换输出结果,如下图所示。例如,可以将一个字符串类型的数据拆分开作为元组输出;也可以对数据做一些计算,比如每个代表数量的字段加1。我们之前讲到的基本转换算子,如map、filter、flatMap,计算时不依赖其他数据,就都属于无状态的算子。
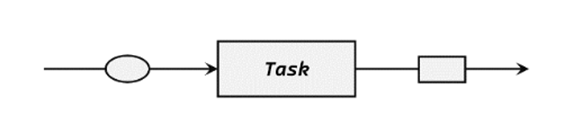
而有状态的算子任务,则除当前数据之外,还需要一些其他数据来得到计算结果。这里的“其他数据”,就是所谓的状态(state),最常见的就是之前到达的数据,或者由之前数据计算出的某个结果。比如,做求和(sum)计算时,需要保存之前所有数据的和,这就是状态;窗口算子中会保存已经到达的所有数据,这些也都是它的状态。另外,如果希望检索到某种“事件模式”(event pattern),比如“先有下单行为,后有支付行为”,那么也应该把之前的行为保存下来,这同样属于状态。容易发现,之前讲过的聚合算子、窗口算子都属于有状态的算子。
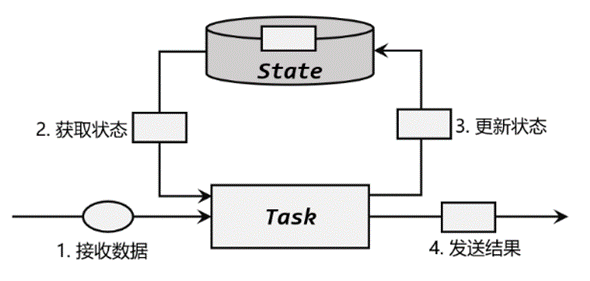
如上图所示为有状态算子的一般处理流程,具体步骤如下。(1)算子任务接收到上游发来的数据;(2)获取当前状态;(3)根据业务逻辑进行计算,更新状态;(4)得到计算结果,输出发送到下游任务。
2、状态的管理
在传统的事务型处理架构中,这种额外的状态数据是保存在数据库中的。而对于实时流处理来说,这样做需要频繁读写外部数据库,如果数据规模非常大肯定就达不到性能要求了。所以Flink的解决方案是,将状态直接保存在内存中来保证性能,并通过分布式扩展来提高吞吐量。在Flink中,每一个算子任务都可以设置并行度,从而可以在不同的slot上并行运行多个实例,我们把它们叫作“并行子任务”。而状态既然在内存中,那么就可以认为是子任务实例上的一个本地变量,能够被任务的业务逻辑访问和修改。这样看来状态的管理似乎非常简单,我们直接把它作为一个对象交给JVM就可以了。然而大数据的场景下,我们必须使用分布式架构来做扩展,在低延迟、高吞吐的基础上还要保证容错性,一系列复杂的问题就会随之而来了。
状态的访问权限。我们知道Flink上的聚合和窗口操作,一般都是基于KeyedStream的,数据会按照key的哈希值进行分区,聚合处理的结果也应该是只对当前key有效。然而同一个分区(也就是slot)上执行的任务实例,可能会包含多个key的数据,它们同时访问和更改本地变量,就会导致计算结果错误。所以这时状态并不是单纯的本地变量。
容错性,也就是故障后的恢复。状态只保存在内存中显然是不够稳定的,我们需要将它持久化保存,做一个备份;在发生故障后可以从这个备份中恢复状态。
我们还应该考虑到分布式应用的横向扩展性。比如处理的数据量增大时,我们应该相应地对计算资源扩容,调大并行度。这时就涉及到了状态的重组调整。
可见状态的管理并不是一件轻松的事。好在Flink作为有状态的大数据流式处理框架,已经帮我们搞定了这一切。Flink有一套完整的状态管理机制,将底层一些核心功能全部封装起来,包括状态的高效存储和访问、持久化保存和故障恢复,以及资源扩展时的调整。这样,我们只需要调用相应的API就可以很方便地使用状态,或对应用的容错机制进行配置,从而将更多的精力放在业务逻辑的开发上。
3、状态的分类
1. 托管状态(Managed State)和原始状态(Raw State)
Flink的状态有两种:托管状态(Managed State)和原始状态(Raw State)。托管状态就是由Flink统一管理的,状态的存储访问、故障恢复和重组等一系列问题都由Flink实现,我们只要调接口就可以;而原始状态则是自定义的,相当于就是开辟了一块内存,需要我们自己管理,实现状态的序列化和故障恢复。具体来讲,托管状态是由Flink的运行时(Runtime)来托管的;在配置容错机制后,状态会自动持久化保存,并在发生故障时自动恢复。当应用发生横向扩展时,状态也会自动地重组分配到所有的子任务实例上。对于具体的状态内容,Flink也提供了值状态(ValueState)、列表状态(ListState)、映射状态(MapState)、聚合状态(AggregateState)等多种结构,内部支持各种数据类型。聚合、窗口等算子中内置的状态,就都是托管状态;我们也可以在富函数类(RichFunction)中通过上下文来自定义状态,这些也都是托管状态。而对比之下,原始状态就全部需要自定义了。Flink不会对状态进行任何自动操作,也不知道状态的具体数据类型,只会把它当作最原始的字节(Byte)数组来存储。我们需要花费大量的精力来处理状态的管理和维护。所以只有在遇到托管状态无法实现的特殊需求时,我们才会考虑使用原始状态;一般情况下不推荐使用。绝大多数应用场景,我们都可以用Flink提供的算子或者自定义托管状态来实现需求。
2. 算子状态(Operator State)和按键分区状态(Keyed State)
接下来我们的重点就是托管状态(Managed State)。我们知道在Flink中,一个算子任务会按照并行度分为多个并行子任务执行,而不同的子任务会占据不同的任务槽(task slot)。由于不同的slot在计算资源上是物理隔离的,所以Flink能管理的状态在并行任务间是无法共享的,每个状态只能针对当前子任务的实例有效。而很多有状态的操作(比如聚合、窗口)都是要先做keyBy进行按键分区的。按键分区之后,任务所进行的所有计算都应该只针对当前key有效,所以状态也应该按照key彼此隔离。在这种情况下,状态的访问方式又会有所不同。基于这样的想法,我们又可以将托管状态分为两类:算子状态和按键分区状态。
(1)算子状态(Operator State)状态作用范围限定为当前的算子任务实例,也就是只对当前并行子任务实例有效。这就意味着对于一个并行子任务,占据了一个“分区”,它所处理的所有数据都会访问到相同的状态,状态对于同一任务而言是共享的,
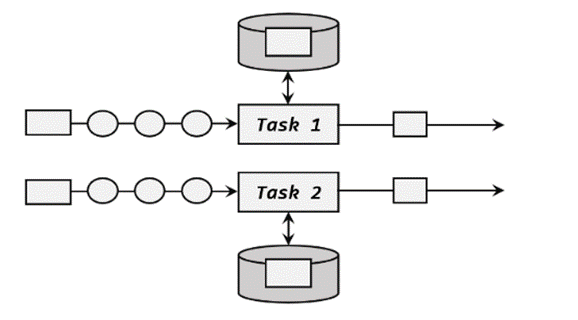
算子状态可以用在所有算子上,使用的时候其实就跟一个本地变量没什么区别——因为本地变量的作用域也是当前任务实例。在使用时,我们还需进一步实现CheckpointedFunction接口。
2)按键分区状态(Keyed State)状态是根据输入流中定义的键(key)来维护和访问的,所以只能定义在按键分区流(KeyedStream)中,也就keyBy之后才可以使用,
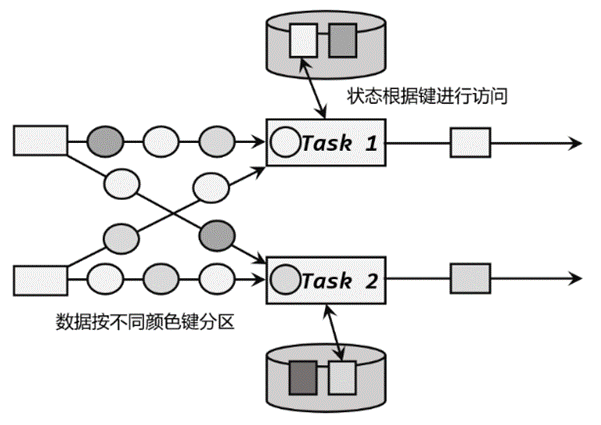
按键分区状态应用非常广泛。之前讲到的聚合算子必须在keyBy之后才能使用,就是因为聚合的结果是以Keyed State的形式保存的。另外,也可以通过富函数类(Rich Function)来自定义Keyed State,所以只要提供了富函数类接口的算子,也都可以使用Keyed State。所以即使是map、filter这样无状态的基本转换算子,我们也可以通过富函数类给它们“追加”Keyed State,或者实现CheckpointedFunction接口来定义Operator State;从这个角度讲,Flink中所有的算子都可以是有状态的,不愧是“有状态的流处理”。无论是Keyed State还是Operator State,它们都是在本地实例上维护的,也就是说每个并行子任务维护着对应的状态,算子的子任务之间状态不共享。
6. 小结
7. 参考文献
[1] 百度百科,https://baike.baidu.com/item/%E6%9F%8F%E6%9E%97%E5%B7%A5%E4%B8%9A%E5%A4%A7%E5%AD%A6/2567790?fr=aladdin
[2] stratosphere研究项目刊物http://stratosphere.eu/project/publications/
[3] https://blog.csdn.net/wellto/article/details/75281488